StyleGAN:A Style-Based Generator Architecture for Generative Adversarial Networks
StyleGAN : A Style-Based Generator Architecture for Generative Adversarial Networks 를 읽고 정리한 글입니다.
StyleGAN : A Style-Based Generator Architecture for Generative Adversarial Networks (CVPR 2019)
Overview
GAN의 generator 부분은 black box로 여겨져 이미지 생성 과정을 이해하기 어려웠음.
style transfer에서 기반한 generator 구조- 각 레이어마다 style의 정보를 입힘. ->
AdaIN - 전체적인 스타일(머리 색, 인종, 성별 등), 세세한 부분(곱슬 등) 등까지 조정 가능 ->
noise
- 각 레이어마다 style의 정보를 입힘. ->
- baseline :
progressive GAN- latent vector로 부터 이미지 합성하고 점점 해상도를 올려서 high-resolution image 생성 => scale-specific control
loss function, discriminator 등 수정하지 않고 오직 제너레이터에 대해서만 다룸.
- latent space의 interpolation quality 측정하는 measure 제안
- perceptual path length
- linear separability
- FFHQ 데이터셋 오픈
Related work (Basic concepts)
- Progressive GAN
- GAN을 저해상도에서 고해상도로 점진적으로 학습
- style transfer
- content image & style image가 있을 때 content 이미지와 유사하게 style image에 입히는 것
Methods
(Explain one of the methods that the thesis used.)
Generator Architecture

left : traditional generaotr : latent code
z를 input layer에 바로 넣음.right : style-based generator
- first, map the input to an intermediate latent space
W. - then controls the generator through adaptive instance normalization (AdaIN) at each conv. layer.
- Gaussian noise is added after each conv.
- first, map the input to an intermediate latent space
제안한 모델을 차근차근 뜯어보자면
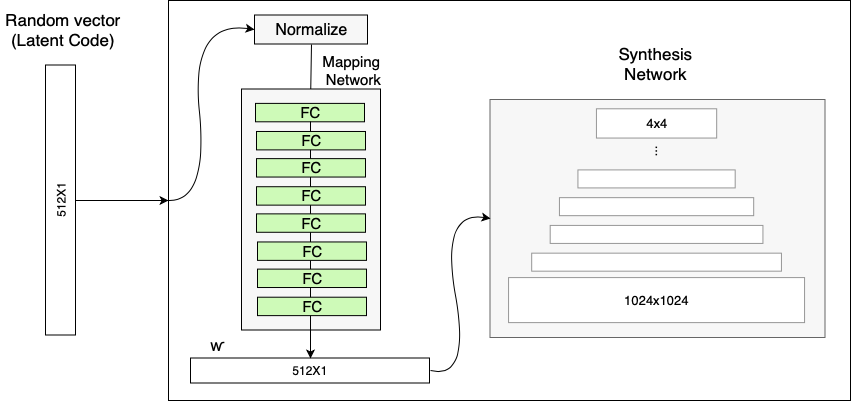
Mapping Network
https://towardsdatascience.com/explained-a-style-based-generator-architecture-for-gans-generating-and-tuning-realistic-6cb2be0f431
input vector z를 바로 input layer에 넣는 것이 아니라, mapping network를 거쳐 intermediate vector w 로 변환한 후 이미지를 생성한다.
- 바로 인풋 레이어에 넣지 않는 이유 : 고정된 input distribution에 맞춰야 해서 non-linear하게 mapping이 되고, 이것은 머리 색등과 같은 attribute를 변경하기 힘들어지기 때문.
- 위처럼 intermediate vector를 사용하게 되면 유동적인 공간에 mapping 시킬 수 있기 때문에 visual attribute 조절이 쉬워진다. => disentanglement 하다.
즉, 이 네트워크에서는 z로부터 만들어진 style w를 구하고, 이를 affine transformation을 거친 A를 synthesis network에 넘겨주어 AdaIN operation을 통해 레이어에 스타일을 입힌다.
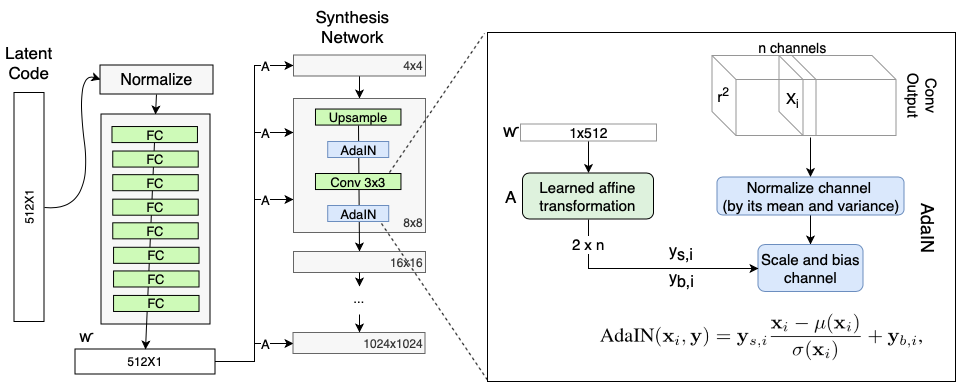
Style Modules (AdaIN)
https://towardsdatascience.com/explained-a-style-based-generator-architecture-for-gans-generating-and-tuning-realistic-6cb2be0f431

- 위에서 생성된
w는 style에 대한 정보를 가지고 있다. - Synthesis network는 학습가능한 constant tensor(4x4x512)를 upsampling, convolution을 통해 1024x1024x3 이미지로 변환시킨다.
- w의 affine transfomation을 통해 얻어진 A를 가지고 AdaIN operation을 통해 스타일을 입힌다.
- normalize하고, 이를 scale하고 bias를 더함. 이게 스타일을 입히는 효과를 낸다.
- 매 conv 레이어마다 하므로, 각각의 레이어마다 다른 스타일을 조정할 수 있다. 이 말은 곧, 각 레이어가 특정한 attribute만을 담당한다는 뜻.
- 세밀한 스타일 조정 가능해진다.
Stochastic variation

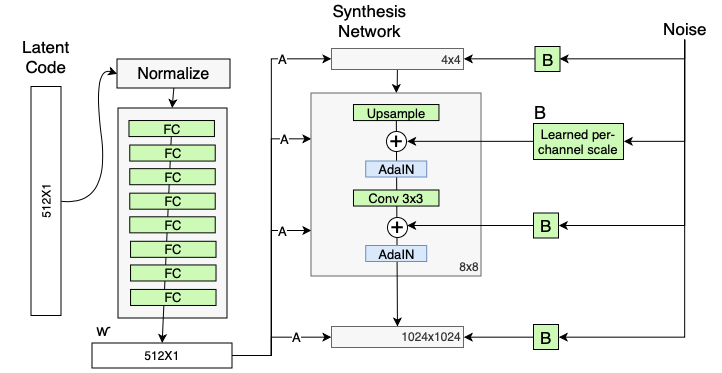
머리카락, 수염 등 stochastic한 요소들은 사진의 디테일에 매우 중요함.
- 위의 architecture에서 noise가 이에 대한 역할을 한다.
- synthesis network에서 by adding per-pixel noise after each convolution.
Style Mixing
two random latent codes(w1,w2)를 사용하는 regularization 기법
- 하나의 w로 학습할 경우 여러 레이어에 대한 style이 correlate되는 문제점이 생길 수 있음.
- ex. w1 스타일로 입혀놓지만, 랜덤으로 몇 개는 w2 스타일을 사용한다 …
- 위와 같은 방법을 통해 각 레이어가 담당하는 스타일을 명확하게 구분지을 수 있다.
- (dropout과 비슷한 원리라고 함)
Disentanglement studies
- 이 내용이 어려워서 제대로 이해하지 못함. 짧게 요약하겠음.

- Disentanglment : latent space가 선형적인 구조를 가지게 되어, 하나의 factor가 움직였을 때 정해진 특성이 바뀌게 만드는 것.
- 예. z의 특정한 값을 바꿨을 때 생성되는 이미지의 하나의 특성(성별, 머리카락 길이 등)만 영향을 주게 되는 것
- fixed distribution을 따르게 되면 억지로 끼워맞추게 되어 어색한 이미지가 만들어질 수 있음.
- 하지만 이 모델처럼 비선형 mapping function을 가지게 될 경우, 고정된 분포를 따를 필요가 없음.
- 위 그림에서 (c)와 같은 형태가 됨. 어느정도 a와 생김새가 비슷하면서 자연스럽게 맞출 수 있게 된 것
A major benefit of our generator architecture is that the intermediate latent space W does not have to support sam-pling according to any fixed distribution; its sampling density is induced by the learned piecewise continuous mapping f(z).
- 본 논문에서는 disentanglement를 학습할 수 있는 두 가지 평가 지표를 제안함.
- Perceptual path length
- Linear seperability
- 위의 내용을 자세히 알고 싶다면 이 곳을 참조
Conclusion
our investigations to the separation of high-level attributes and stochastic effects, as well as the linearity of the intermediate latent space will prove fruitful in improving the understanding and controllability of GAN synthesis.
Appendix. Truncation trick in W
트레이닝 중에 하는 게 아니고, generator가 만든 것 중에 더 나은 latent space 을 뽑는 법에 대한 trick
학습이 완료된 네트워크의 input을 제어하는 방법

위 수식을 통한 w' vector를 뽑는다.
Additional studies
(If you have some parts that cannot understand, you have to do additional studies for them. It’s optional.)
disentanglement에 대한 명확한 이해가 필요함.
References
(References for your additional studies)
- https://www.youtube.com/watch?v=TWzEbMrH59o&feature=youtu.be
- https://towardsdatascience.com/explained-a-style-based-generator-architecture-for-gans-generating-and-tuning-realistic-6cb2be0f431
- https://jayhey.github.io/deep%20learning/2019/01/16/style_based_GAN_2/
- https://blog.lunit.io/2019/02/25/a-style-based-generator-architecture-for-generative-adversarial-networks/